网易数帆Arctic即将开源,助推湖仓一体落地
秉承网易数帆“架构开放,内核开源”的理念,Arctic即将开源!
8月11日,网易数帆将举办“企业级流式湖仓服务 Arctic 开源发布会”,邀请网易数帆大数据产品线及合作伙伴相关负责人联袂解读对数据技术演进及 Arctic 开源的思考,介绍 Arctic 项目进展、未来发展及社区规划,分享企业湖仓一体实践成果与心得。

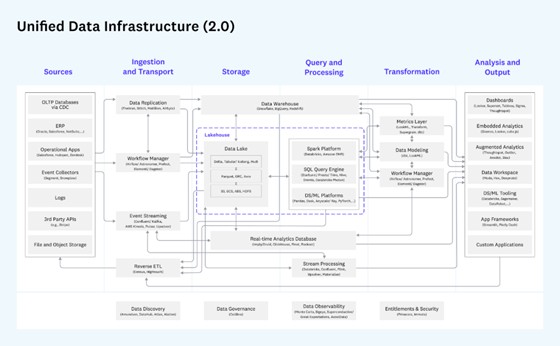
数据基础设施发展的脚步从未停歇,当前风头正盛的是湖仓一体(Lakehouse)。
湖仓一体,顾名思义是数据湖和数据仓库优势的结合。随着企业数智化的推进,湖仓一体已不仅仅是开源社区的热点技术,硅谷顶尖风头投机构A16Z版图的视野中心,更是众多大数据商业产品家族的重要成员。
那么,湖仓一体真的会成为企业大数据基础设施的标准?我们是否应当关注这一技术?它的未来是什么?
为什么需要湖仓一体
借用Databricks的定义,湖仓一体平台能同时提供数据仓库的可靠性、强大的治理和性能,以及数据湖的开放性、灵活性和机器学习支持。网易数帆湖仓一体项目负责人马进认为,湖仓一体是接力Apache Hadoop蓬勃生态的新赛道,它的核心特性就是在数据湖上构建事务层,把数据处理和管理高级功能嫁接到低成本数据存储架构上。这是业务需求驱动的架构演进,毕竟业务数据类型及规模不断扩大,而对计算实时性的要求又更高。
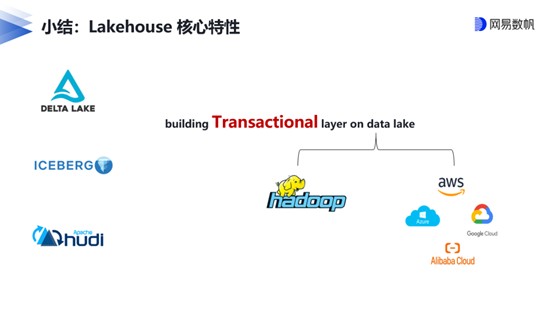
以网易为例,从T+1 离线数据生产,到引入实时化并不断完善,如引入Apache Kudu解决Hive离线数仓在实时数据更新上的不足,形成了流批分割的Lambda架构(这也是业界大数据架构演进的一个缩影),然后数据孤岛、研发体系割裂以及指标和语义的二义性等问题逐渐暴露,这就需要一个更加优雅的统一数据基础设施架构,也就是湖仓一体来解决。基于数据湖开源三剑客(Delta Lake、Apache Iceberg、Apache Hudi)的实现方案,则成为了热门的选择。
网易数帆流式湖仓的创新
尽管在造词法上Lakehouse确实是Data Lake和Data Warehouse的缝合怪,然而要成为生产级的新技术,湖仓一体毕竟不是数据湖和数据仓库1+1=2那么简单。在马进看来,目前湖仓一体方案存在两大不足:一是所读即所写,会产生流式摄取导致海量小文件等问题;二是实时能力不足,比如基于湖仓一体的流计算延迟在分钟级别。
基于此,马进带领团队研发了命名为Arctic的流式湖仓服务,提出了五个设计目标:提供可靠的湖仓一体服务,解决主流湖仓一体的不足,面向更多流批一体的场景,尽可能不要重复造轮子,和寻求代际型解决方案。
技术方案上,Arctic搭建在Iceberg表格式之上,复用Iceberg各种功能,并完全兼容Hive。Arctic面向流场景提供优化的CDC(变更数据获取)和流式更新能力,也可以开放式地集成 MQ、KV 等中间件,向 Flink、Spark、Trino 等主流计算引擎提供流批统一的表服务,以实现数据湖和数仓的统一,并融入实时的能力,流计算延迟可达毫秒级。
由此,Arctic 可视为一个独立的实时数仓服务,用户无需关心数据存储结构、大小和分布,或是否引入其他中间件。
流式湖仓的未来
三十年前,西方学者面对社会变迁发出“历史的终结”的感慨,但历史已经给这一论断打脸。那么,流式湖仓又是否会成为现代大数据基础架构的终点?回顾数据分析领域,先后出现的数据仓库、OLAP、BI、大数据、数据中台等各种方法论,都已融入企业数据生命周期,而底层的Hadoop体系依然在广泛使用,我们有理由相信,流式湖仓服务这一源自业务需求的设计,实现方式可能会升级,但这一思想必将长存于数据基础设施。
从A16Z的全景图我们也可以看到,企业级数据基础设施架构的稳定往往伴随着长时间的沉淀,而Arctic开放的架构及对Hadoop生态的兼容,已经预示着它的生命力。


